Benchmarking Unsupervised Object Representations for Video Sequences
2021
Article
avg
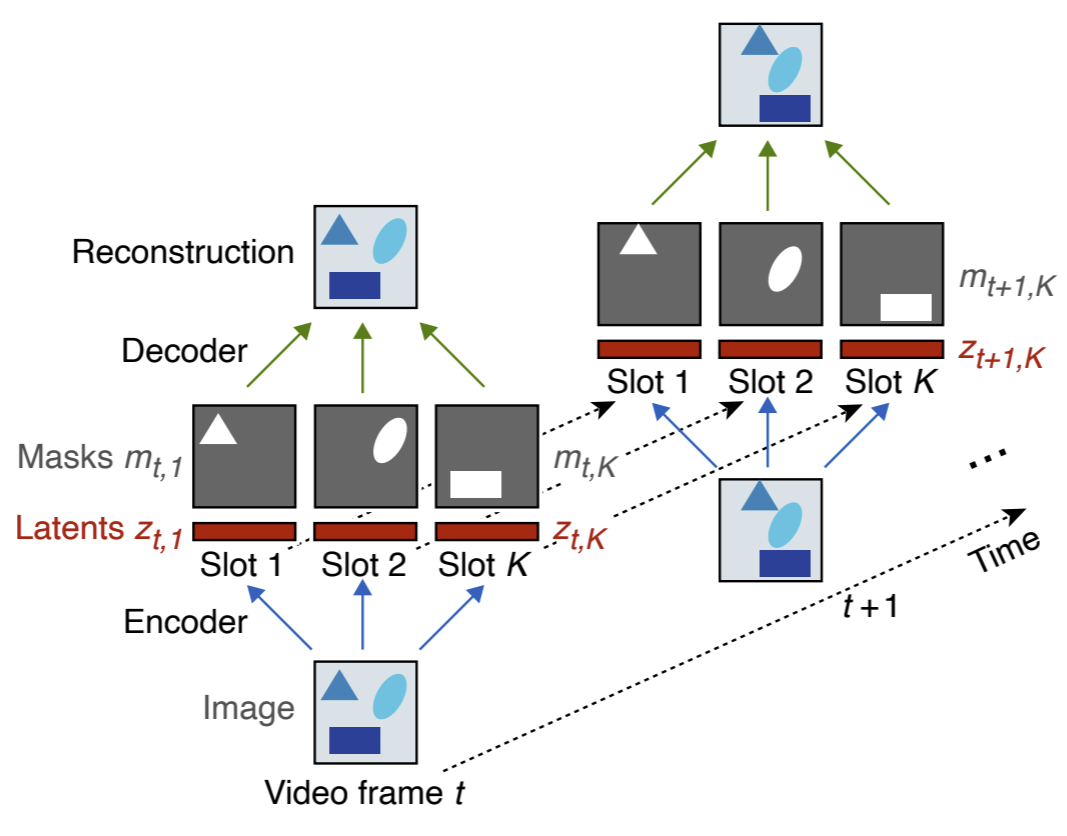
Perceiving the world in terms of objects and tracking them through time is a crucial prerequisite for reasoning and scene understanding. Recently, several methods have been proposed for unsupervised learning of object-centric representations. However, since these models were evaluated on different downstream tasks, it remains unclear how they compare in terms of basic perceptual abilities such as detection, figure-ground segmentation and tracking of objects. To close this gap, we design a benchmark with four data sets of varying complexity and seven additional test sets featuring challenging tracking scenarios relevant for natural videos. Using this benchmark, we compare the perceptual abilities of four object-centric approaches: ViMON, a video-extension of MONet, based on recurrent spatial attention, OP3, which exploits clustering via spatial mixture models, as well as TBA and SCALOR, which use explicit factorization via spatial transformers. Our results suggest that the architectures with unconstrained latent representations learn more powerful representations in terms of object detection, segmentation and tracking than the spatial transformer based architectures. We also observe that none of the methods are able to gracefully handle the most challenging tracking scenarios despite their synthetic nature, suggesting that our benchmark may provide fruitful guidance towards learning more robust object-centric video representations.
| Author(s): | Marissa Weis and Kashyap Chitta and Yash Sharma and Wieland Brendel and Matthias Bethge and Andreas Geiger and Alexander Ecker |
| Journal: | Journal of Machine Learning Research (JMLR) |
| Volume: | 22 |
| Pages: | 61 |
| Year: | 2021 |
| Department(s): | Autonomous Vision |
| Bibtex Type: | Article (article) |
| State: | Published |
| URL: | http://jmlr.org/papers/v22/21-0199.html |
| Links: |
Paper
Project page |
|
BibTex @article{Weis2021JMLR,
title = {Benchmarking Unsupervised Object Representations for Video Sequences},
author = {Weis, Marissa and Chitta, Kashyap and Sharma, Yash and Brendel, Wieland and Bethge, Matthias and Geiger, Andreas and Ecker, Alexander},
journal = {Journal of Machine Learning Research (JMLR)},
volume = {22},
pages = {61},
year = {2021},
doi = {},
url = {http://jmlr.org/papers/v22/21-0199.html}
}
|
|