2023

KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D
2021
Learning Steering Kernels for Guided Depth Completion
Liu, L., Liao, Y., Wang, Y., Geiger, A., Liu, Y.
IEEE Transactions on Image Processing , 30, pages: 2850-2861, IEEE, February 2021 (article)

SMD-Nets: Stereo Mixture Density Networks
Tosi, F., Liao, Y., Schmitt, C., Geiger, A.
Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (article)
Zoomorphic Gestures for Communicating Cobot States
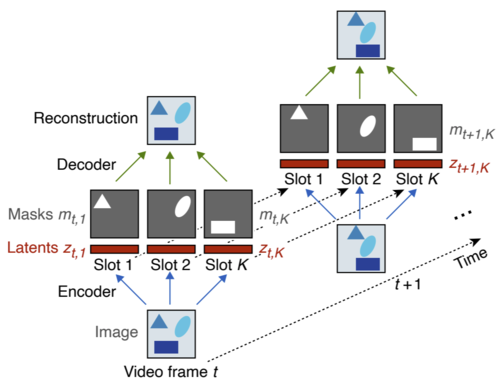
Benchmarking Unsupervised Object Representations for Video Sequences
Weis, M., Chitta, K., Sharma, Y., Brendel, W., Bethge, M., Geiger, A., Ecker, A.
Journal of Machine Learning Research (JMLR), 22, pages: 61, 2021 (article)
2020
Self-Supervised Linear Motion Deblurring
Liu, P., Janai, J., Pollefeys, M., Sattler, T., Geiger, A.
IEEE Robotics and Automation Letters, 5(2):2475-2482, IEEE, April 2020 (article)
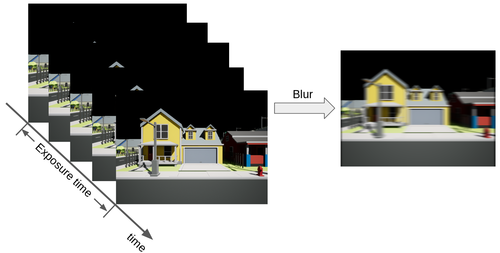
Self-supervised motion deblurring
Liu, P., Janai, J., Pollefeys, M., Sattler, T., Geiger, A.
IEEE Robotics and Automation Letters, 2020 (article)
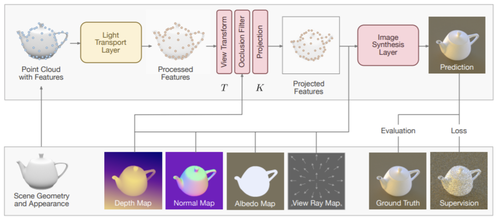
Learning Neural Light Transport
Sanzenbacher, P., Mescheder, L., Geiger, A.
Arxiv, 2020 (article)
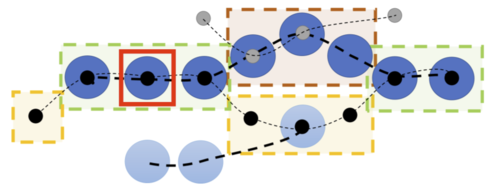
HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Luiten, J., Osep, A., Dendorfer, P., Torr, P., Geiger, A., Leal-Taixe, L., Leibe, B.
International Journal of Computer Vision, 129(2):548-578, 2020 (article)
2018
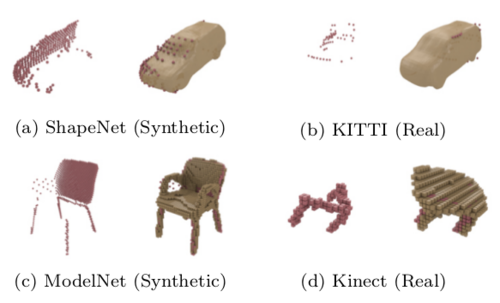
Learning 3D Shape Completion under Weak Supervision

Augmented Reality Meets Computer Vision: Efficient Data Generation for Urban Driving Scenes
Alhaija, H., Mustikovela, S., Mescheder, L., Geiger, A., Rother, C.
International Journal of Computer Vision (IJCV), 2018, 2018 (article)
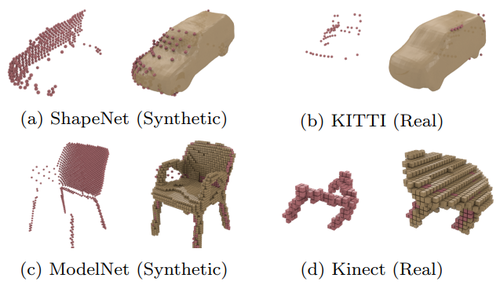
Learning 3D Shape Completion under Weak Supervision

Object Scene Flow
Menze, M., Heipke, C., Geiger, A.
ISPRS Journal of Photogrammetry and Remote Sensing, 2018 (article)
2016
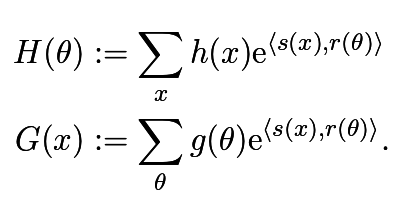
Probabilistic Duality for Parallel Gibbs Sampling without Graph Coloring
Mescheder, L., Nowozin, S., Geiger, A.
Arxiv, 2016 (article)
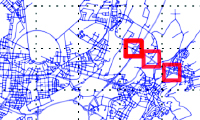
Map-Based Probabilistic Visual Self-Localization
Brubaker, M. A., Geiger, A., Urtasun, R.
IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), 2016 (article)
2015
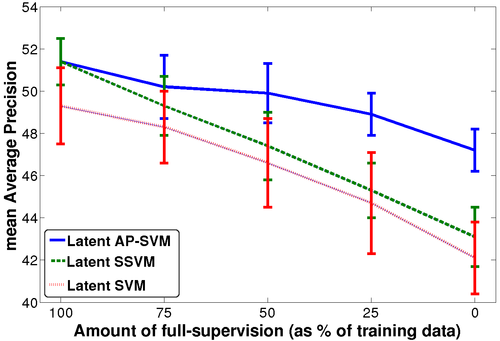
Optimizing Average Precision using Weakly Supervised Data
Behl, A., Mohapatra, P., Jawahar, C. V., Kumar, M. P.
IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), 2015 (article)
2014
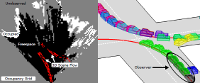
3D Traffic Scene Understanding from Movable Platforms
Geiger, A., Lauer, M., Wojek, C., Stiller, C., Urtasun, R.
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 36(5):1012-1025, published, IEEE, Los Alamitos, CA, May 2014 (article)
2013

Vision meets Robotics: The KITTI Dataset
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.
International Journal of Robotics Research, 32(11):1231 - 1237 , Sage Publishing, September 2013 (article)