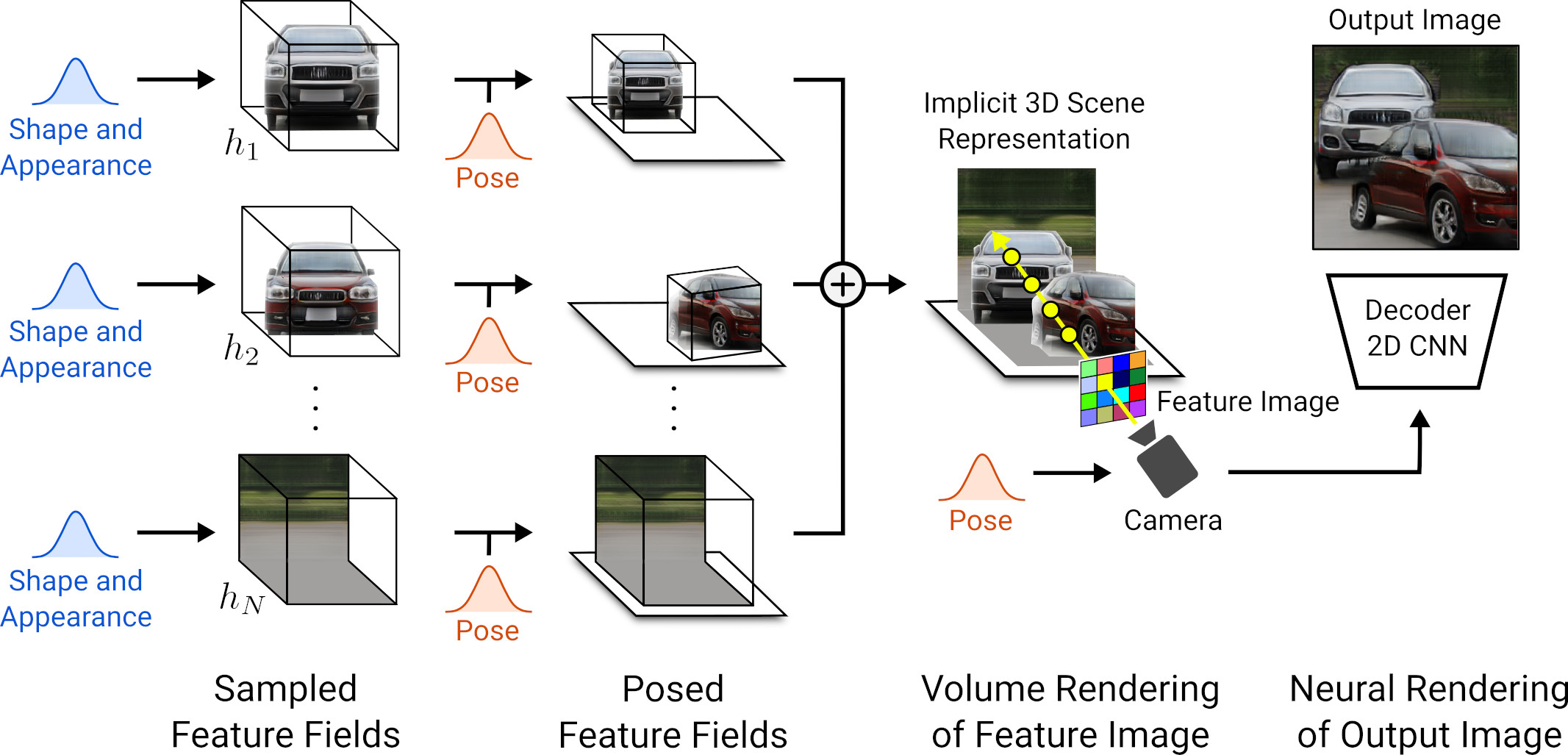
By representing scenes as Compositional Generative Neural Feature Fields, we gain explicit control over the pose and appearance of individual objects in synthesized images.
A generative model like a Variational Auto-Encoder (VAE) or Generative Adversarial Network (GAN) is able to synthesize diverse and high-quality images that closely resemble the images from the training dataset. However, the generation process of these models lacks controllability. In particular, users may want to adjust the 3D pose and size of objects in the synthesized images. Ideally, the scene's layout can be altered without changing other aspects like the overall geometry or texture of the individual objects.
Endowing a generative model with such 3D controllability requires 3D understanding. Traditionally, in 3D Reconstruction, geometry is inferred from a set of posed images of a single scene. In contrast, our algorithms observe images from multiple scenes. In the most challenging setting we studied, there is only a single image per scene given. Therefore, our research constitutes an important step towards gaining 3D understanding from arbitrary image collections.
In our pioneering work [ ], we were the first to develop a method that allows for synthesizing multi-object scenes that are consistent wrt. changes in viewpoint or object pose.
In our second work on the subject, we developed Generative Radiance Fields (GRAFs) [ ], a model capable of synthesizing images of complex objects with higher fidelity. This was achieved by using a neural radiance field (NeRF) for representing the 3-dimensional content of the scene. A NeRF is a deep neural network that maps 3D position and 2D viewing direction continuously maps these quantities to volumetric density and color. This scalable scene representation is strongly influenced by our works on neural implicit representations; please refer to the correspondent research project. Volumetric rendering of the NeRF representation ensures consistent synthesis results across viewpoints.
With Compositional Generative Neural Feature Fields (GIRAFFE) [ ] we extended GRAF's methodology to multi-object scenes. To enable the manipulation of individual objects, we represent each object with a separate feature field. Instead of color, we associate a feature vector with each 3D point. Volumetric rendering of the GIRAFFE results in a 2D feature image, which is converted by a convolutional network into the final image. This novel combination of volumetric and neural rendering leads to detailed results at a low cost.
For the work introducing GIRAFFEs, we received the best paper award at CVPR 2021.