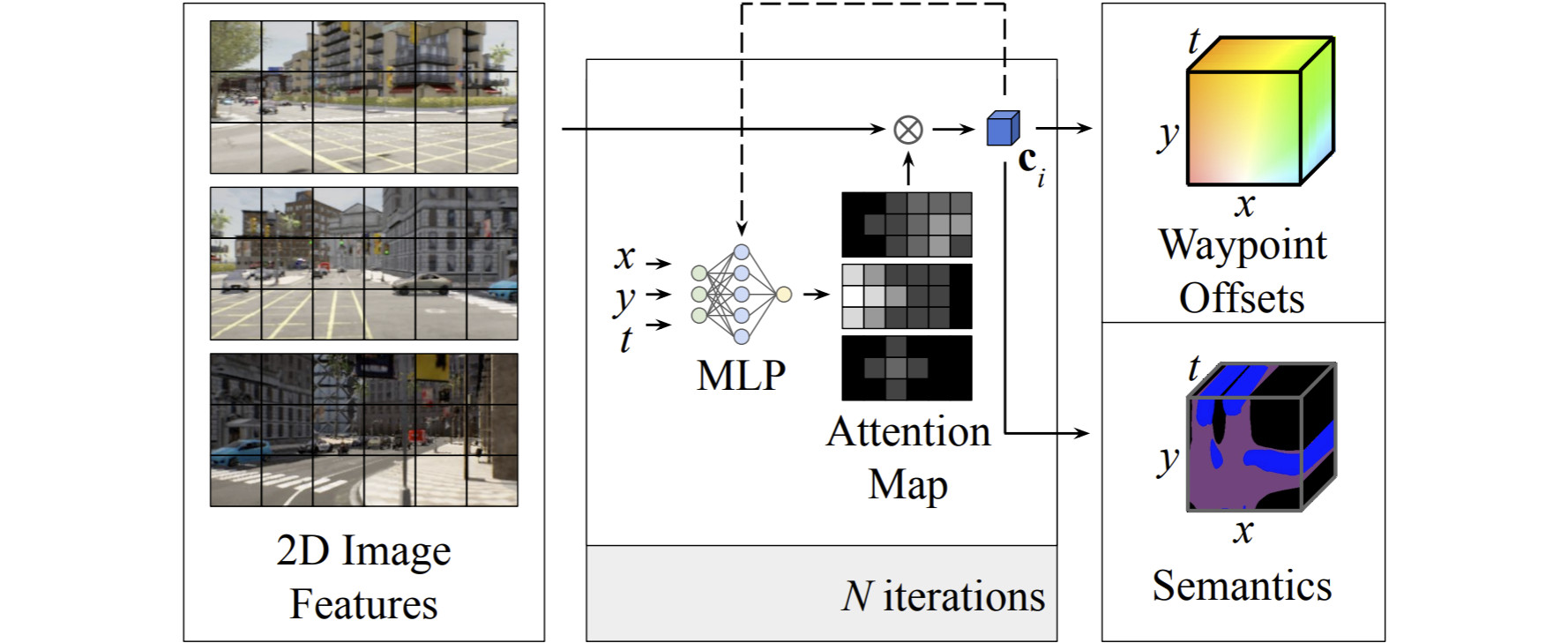
We developed Neural Attention Fields as intermediate representation for predicting waypoint offsets and Bird’s Eye View semantics. Intermediate attention maps are used to iteratively compress high-dimensional 2D image features into a compact representation useful for the downstream task of autonomous driving.
For autonomous driving, raw sensor inputs (RGB images, LiDAR) are transformed into a high-level representation, that is more suitable for decision making on the road. However, it is not clear what is the most adequate intermediate representation and how to obtain a particular representation from raw inputs. We, therefore, studied several alternative representations and developed a learning pipeline for each representation to efficiently and accurately estimate it from the car's sensors.
Towards this goal, we trained a neural network that predicts from the RGB feed information useful for the self-driving task like distance to the centerline or to the lead vehicle [ ]. Since some of these affordances like the presence of a relevant red light also depend on the self-driving car's route we additionally condition the network on directional inputs. In the challenging CARLA simulation benchmark for goal-directed navigation, our approach is the first to handle traffic lights, speed signs and smooth car-following, resulting in a significant reduction of accidents.
How should representations from complementary sensors be integrated for autonomous driving? Geometry-based fusion has shown great promise for tasks such as object detection. However, for the driving task, the global context of the 3D scene is key, e.g. a change in traffic light state can affect the behavior of a vehicle geometrically distant from that traffic light. Geometry alone is therefore insufficient for fusing representations in driving models. To tackle this issue, we introduced TransFuser, a novel Multi-Modal Fusion Transformer, to integrate image and LiDAR representations using attention [ ]. Our approach achieves state-of-the-art driving performance on CARLA while reducing collisions by 76\% compared to geometry-based fusion.
With NEural ATtention fields (NEAT), we developed a novel representation that enables efficient reasoning about the semantic, spatial, and temporal structure for end-to-end imitation learning models [ ]. NEAT is inspired by our work on neural implicit representations [ ] and maps locations in Bird's Eye View (BEV) scene coordinates to waypoints and semantics, using intermediate attention maps to iteratively compress high-dimensional 2D image features into a compact representation. This allows our model to selectively attend to relevant regions in the input while ignoring information irrelevant to the driving task, effectively associating the images with the BEV representation. Visualizing the attention maps for models with NEAT intermediate representations provides interpretability.