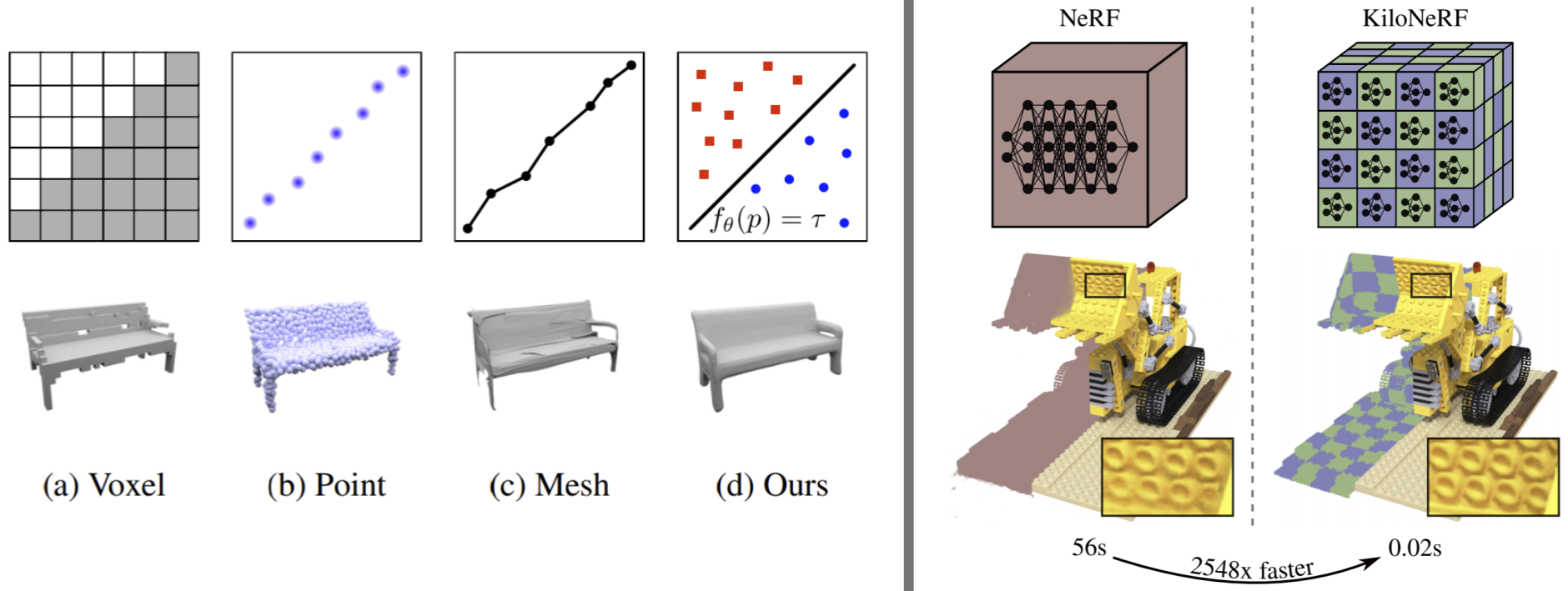
Left: By representing a scene as the decision boundary of a deep neural network we do away with the issues of classical 3D representations (voxel, point could and mesh). Right: Our hybrid between neural and voxel representation enables real-time rendering.
We live in a three-dimensional world, thus proper 3D understanding is crucial for autonomous systems like self-driving cars. But first, a suitable representation for the three-dimensional content of our world is required. Traditionally, point cloud, voxel or mesh representations are used, but point clouds lack connectivity information, voxels are memory hungry and meshes are hard to integrate into deep learning pipelines. To address these problems, we developed neural implicit representations (NIR), that compactly encode the geometry of a scene in the weights of a deep neural network (DNN) [ ].
We extended NIRs to handle time-varying topologies by introducing Occupancy Flow, a novel spatio-temporal representation of time-varying 3D geometry. Implicitly, our model yields correspondences over time, thus enabling fast inference while providing a sound physical description of the temporal dynamics [ ].
For texture reconstruction of 3D objects, we introduced Texture Fields, a novel representation that is based on regressing a continuous 3D function parameterized with a neural network. Texture Fields are able to represent high-frequency details and blend naturally with modern deep learning techniques [ ]. Further, we developed Surface Light Fields, where we additionally condition the neural network on the location and color of a small light source [ ]. This allows us to manipulate the light source and relight captured objects using environment maps.
By combining NIR with convolutional neural networks we can perform 3D reconstruction of large scenes from point clouds [ ].
The aforementioned works rely on 3D supervision, which might not be always available. We showed that by differentiably rendering our NIR, we can solve for the geometry and appearance of a scene even when only posed 2D images are available for supervision [ ]. In follow-up work, we increased the practicality of this method by removing the dependence on expensive-to-collect image masks [ ].
A downside of NIRs is that they cannot be efficiently rendered without prior conversion to a voxel or mesh representation. To tackle this issue, we designed a hybrid between NIRs and voxels. This representation can be directly rendered in real-time but still has a small memory footprint [ ].
Finally, we developed differentiable forward skinning for NIRs which enables the animation of articulated 3D objects like humans from posed meshes alone [ ].